Billion-row challenge: Rust walkthrough
A few weeks ago, I watched my daily primetime video and it featured the billion-row challenge. I first chugged it off because I immediately saw the J-word ( I’ll say it this time … Java 🤮 ) sprinkled around. Then I nerd-sniped myself into practicing some Rust and trying to dunk on those GC 1GB VM-needing languages.
In this blog post, I’ll walk through how I optimized my solution so buckle up for that sweet speedup! I forced myself not to look at posted solutions and try to come up with optimizations on my own. I guessed it would be nice to test my profiling skills in Rust and see how deep is my knowledge about all the underlying systems that come into play when solving this challenge.
It’s also pretty fun to see how far I can push myself before comparing my solution to others and see what optimizations I missed. To give you a taste before diving in into what I achieved, here is a comparison of my final solution to the leading one in C++ and the fastest Rust one I could find:
Benchmark on Linux Ryzen 5 3600x @ 4.1Ghz with 32GB RAM running at 3200 MT/s and using all 12 threads. All binaries used a 1 warmup run and ran 5 times
EDIT: After a discussion with the author of the rust implementation @RagnarGrootKoerkamp, it turned out that I had reported a bad benchmark because my CPU doesn’t support PDEP instructions. After rerun the test with
--features no_pdephis implementation matched the C++ one.
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|---|---|---|---|---|
lehuyduc/1brc-simd |
2.010 ± 0.058 | 1.971 | 2.077 | 1.00 ± 0.08 |
RagnarGrootKoerkamp/1brc |
2.004 ± 0.141 | 1.885 | 2.160 | 1.00 |
My implementation |
5.868 ± 0.053 | 5.812 | 5.918 | 2.93 ± 0.21 |
| Command | Mean [s] | Min [s] | Max [s] | Relative |
I’ll come back to these implementations later to discuss what set of optimizations they used that I missed and what are the similarities.
Challenge review
Let’s first start by breaking down the 1 billion row challenge. You’re given a text file (or generate one thanks to @coriolinus ). The file has this structure:
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
...
The solution has to produce the min, mean, and max values per station, alphabetically ordered. Let’s get one thing straight, I won’t adhere to ALL the rules for the challenge, for instance, I won’t do the alphabetic sorting stuff. Also once you have you’re result sorting is not that hard in using Rust’s iterators.
A pretty simple solution would be to :
- Read the file each line at a time
- Parse the line and extract the Station name and the Value.
- Keep a Hashmap of the cities with a
(min, max, count, sum)and update it using the parsed value - Dump the results
0. Sanity checks first
Before starting to write code, I like to have a general sense of the “speed of light” solution, ie. what are the physical limits of my hardware that can’t be optimized. The generated file is ~14GB in size. I put the file on Curical MX500 SSD connected via SATA3, this drive is rated at a theoretical 560MB/s sequential read speed. This means that if no caching is involved and reading this file without any added logic my max would be at 25s. Now the challenge didn’t mention anything about cache and looking very quickly at the leaderboard it seems that people are basing their results on a cached file. Fortunately, I have 32Gb RAM so the whole file can be cached in RAM and go from there.
❗ Small disclaimer:
I developed on both a 2020 Macbook Air M1 and my Linux machine for this project. I’ll try to show benchmarks using both systems. For profilers, I found a great profiler for MacOS: samply. It uses the Firefox profiler as its UI. On Linux, I used cargo-flamegraph with the standard perf tool. I’ll use screenshots from profilers throughout the post, but they usually report the same behavior. I used hyperfine for all the benchmarks with a warmup of 3 runs.
🔺 I’ll use a smaller generated dataset on 1_000_000 row for all the subsequent benchmarks. I’ll be using my Linux for testing the final big file (14Gb one) and using both M1 and Linux for the benchmarks.
1. The “naive solution”
In the first “naive” solution, I just spat out the simple solution in Rust. The thing that could be considered an optimization is using a BufReader to coalesce syscalls for reads, but come on that’s pretty standard and just common sense!
let mut records: HashMap<String, Measurement> = HashMap::new();
let reader = BufReader::with_capacity(4096, file);
for line in reader.lines() {
if let Some((city, value)) = line.unwrap().split_once(";") {
let value = value
.parse::<f32>()
.expect("can't parse value into f32");
records
.entry(city.to_string())
.and_modify(|e| e.append(value))
.or_insert(Measurement {
min: value,
max: value,
sum: value,
count: 0,
});
};
}
Here is the result of running the naive version. Nothing to sing and dance about here but hey that’s a start.
| Command | Mean [ms] | Min [ms] | Max [ms] |
|---|---|---|---|
./target/release/naive |
239.2 ± 2.1 | 236.8 | 241.8 |
2. Better hashing
This one optimization I didn’t use any profiling for. The only required skill here is RTFM. The Rust’s Hashmap mentions:
The default hashing algorithm is currently SipHash 1-3, though this is subject to change at any point in the future. While its performance is very competitive for medium sized keys, other hashing algorithms will outperform it for small keys such as integers as well as large keys such as long strings, though those algorithms will typically not protect against attacks such as HashDoS.
The SipHash 1-3 is high quality but is relatively slow, fortunately, Rust has an amazing ecosystem and faster dropping replacements exist: I’ll use the FxHashMap from rustc-hash crate:
let mut records: FxHashMap<String, Measurement> = FxHashMap::default();
One-liner always feels great! How about performance?
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./target/release/naive |
250.6 ± 1.2 | 248.7 | 252.3 | 1.21 ± 0.01 |
./target/release/naive_hash |
207.0 ± 1.2 | 205.0 | 208.9 | 1.00 |
Well that’s a 1.21X speedup form that one line change, nice !
3. Wait why Strings?
Looking at the flame graph for the naive_hash implementation one blatantly apparent optimization appears:

The std::io::append_to_string takes a lot of time… But why do we need strings again?
Oh right, that reader.lines() function returns Lines struct which can be turned into an iterator of Result<String,_>. This is quite ergonomic but hey we are not really after ergonomy here. The idea is that we don’t need to parse the bytes to strings. This will remove entirely the need to validate the bytes as valid utf8 and directly run everything on &[u8]. We still need to delimit line breaks though. Our reader does have a read_until() method which takes in a byte delimiter and &mut Vec<u8> buffer. The Bufreader will read from the underlying file and push them into the buf. To remove string-parsing altogether, we’ll also change the key type in our hashmap from String to Vec<u8>. I’ll use the .split_once method on the byte slice to separate the station from the value.
Enough talking here is the code :
// Note we only use a single buffer with preallocated memory
let mut buf = Vec::with_capacity(4096);
let mut reader = BufReader::new(file);
while let Ok(n) = reader.read_until(b'\n', &mut buf) {
if n == 0 {
break;
}
let line: &[u8] = &buf[..n - 1];
if let Some((city, value)) = line.split_once(|&b| b == b';') {
let value = unsafe {
String::from_utf8_unchecked(value.to_vec())
.parse::<f32>()
.expect("can't parse value into f32")
};
match records.get_mut(city) {
Some(m) => m.append(value),
None => {
let _res = records.insert(
city.to_owned(),
Measurement {
min: value,
max: value,
sum: value,
count: 0,
},
);
}
};
}
// Clear buffer
buf.clear();
}
Yeah, I know why use unsafe? Well, I know that the value is a valid Utf-8 so I’ll just use a faster path to get the string before parsing to f32. Grow up, deal with it…
I’ll let the benchmark talk:
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./target/release/naive |
250.1 ± 1.4 | 246.9 | 251.7 | 2.12 ± 0.03 |
./target/release/naive_hash |
208.5 ± 3.6 | 205.2 | 219.8 | 1.77 ± 0.04 |
./target/release/naive_hash_bytes |
117.9 ± 1.6 | 116.0 | 124.3 | 1.00 |
Moving from String to bytes yields a 2.12X speedup !
5. Parsing f32 takes time. Remove it!
Let’s now look at the profiling output:
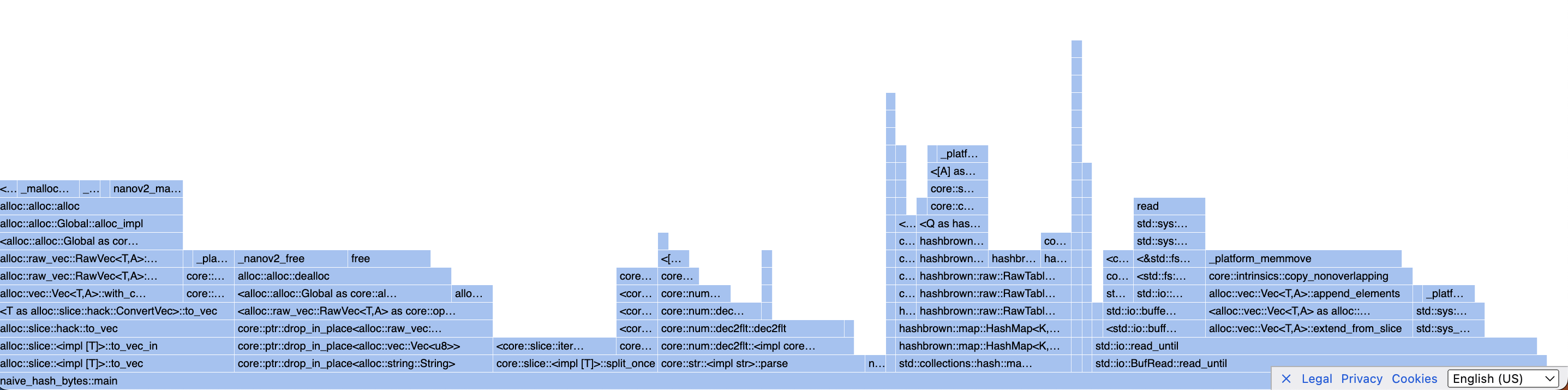
I see two huge blocks that need optimizing here :
read_untilcalls into and extend method that seems to take all the time …- That
drop_in_place<alloc_string>business seems crazy!
Let’s tackle the crazy stuff first (that’s the 2., focus please … ). Recall String is a heap-allocated Object in Rust. We are first parsing the buffer into a String then parsing it to a f32. That’s what crazy! We allocate some memory to only drop it in place! There isn’t a great way to parse f32s from bytes easily in the Rust’s std library. Looking at the values in the files I could see that all of them are between -1000 and 1000 (for sure) and have only 1 decimal point. So what came up with is to statically build at runtime a Hashmap to look up the &[u8]. I’ll use the lazy_static crate for this:
// hashtable to lookup the u8
lazy_static! {
static ref TEMP_VALUES: FxHashMap<Vec<u8>, f32> = {
let mut map = FxHashMap::default();
for int in -1000..=1000 {
for dec in -9..=9 {
if dec == 0 {
let key = format!("{}", int);
map.insert(key.as_bytes().to_vec(), int as f32);
} else {
let val = int as f32 + 0.1 * (dec as f32);
let key = format!("{}", val);
map.insert(key.as_bytes().to_vec(), val);
}
}
}
map.insert("-0".as_bytes().to_vec(), 0.0);
map
};
}
Then remove the parsing f32 logic:
let value = *TEMP_VALUES
.get(byte_value)
.ok_or_else(|| {
format!(
"can't find value {}",
String::from_utf8(byte_value.to_vec()).unwrap()
)
})
.unwrap();
Benchmark time :
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./target/release/naive |
250.9 ± 0.9 | 249.7 | 252.1 | 2.26 ± 0.05 |
./target/release/naive_hash |
206.9 ± 0.9 | 204.9 | 208.4 | 1.86 ± 0.04 |
./target/release/naive_hash_bytes |
115.8 ± 1.6 | 112.6 | 119.2 | 1.04 ± 0.03 |
./target/release/f32_parsing |
111.0 ± 2.2 | 105.5 | 114.5 | 1.00 |
That’s a small improvement but nothing major. 1.04x over the previous version, 2.26 overall.
4. Wandering off into SIMD land
Remember the first of our two big bottlenecks? In a burst of overconfidence, I didn’t look at the read_until method implementation and started thinking about how to replace it. Big mistake. But hey, you live you learn. This section works as a cautionary tale, no shame in that.
What we need is a fast way to figure out where are the line breaks, which means finding the positions of b'\n' in a slice of bytes. Modern CPUs implement SIMD instructions which makes it possible to process vectors of elements at a time. For example, AVX2 instructions in x86 could process 32-u8 elements at a time, which is pretty great! So my smartass thought that that’s an easy way to speed up the code. Let me first explain to you what I came up with and why it was a waste of time.
First, I used the std::simd unstable feature of Rust to have a portable abstraction not bound to any particular hardware architecture. The idea is to read into a fixed-size buffer (let’s say a 4K bytes buffer), chunk into 32 elements and build a Simd array for each chunk. Then all I need to do is compare this Simd vector with one of [b'\n', ..., b'\n'].
fn parse_lb_simd(buf: &[u8], line_breaks: &mut Vec<usize>) {
let simd_line_break: Simd<u8, 32> = u8x32::splat(b'\n');
let simd_positions: Simd<i8, 32> = Simd::from_slice(&(0..32).collect::<Vec<_>>());
let bytes_iter = buf.chunks_exact(SIMD_LANES);
// Find where '\n' are in this buffer using simd
for (chunk_idx, c) in bytes_iter.enumerate() {
let bytes = u8x32::from_slice(c);
let mask = bytes.simd_eq(simd_line_break);
let filtered_positions = mask.select(simd_positions, Simd::from_array([-1i8; SIMD_LANES]));
for pos in filtered_positions.to_array() {
//TODO : branchless
if pos != -1 {
// dbg!(pos as usize);
let global_pos = chunk_idx * SIMD_LANES + pos as usize;
// NOte: I know I have enough capacity
let current_len = line_breaks.len();
unsafe {
let end = line_breaks.as_mut_ptr().add(current_len);
ptr::write(end, global_pos);
line_breaks.set_len(current_len + 1)
}
}
}
}
}
I can then use this mask to compute all the positions of the line breaks. There is one catch here, how do you deal with the remaining? That’s the ugly part, I was exhausted when working on this so I just kept a secondary buffer where I copied the bytes of the remainder, parsed it on the next run and called it a day:
//TODO : for now just copy it
// Now we deal with what comes after the last break
if let Some(&last) = line_breaks.last() {
let length = buf.len() - last;
reminder[0..length].copy_from_slice(&buf[last..]);
}
Now why was that a way of time you would ask? Well, I benched it against the previous version and it didn’t move at ALL! So I was curious about the read_until implementation and there it was memchr::memchr(delim, available). The memchr crate provides heavily optimized routines for string search primitives… This means they are already parsing using SIMD and probably a lot more optimized.
Back to the drawing board, what now?
6. Wait, let’s bring back float parsing…
Let’s look at the profiler for our fastest version to date:

Mmmm, looks like we have a lot of Hashmap::_ in here. I didn’t think about it but the trick for Hashmap lookup involves looking up values in a Hashmap for every single slice of bytes! So I guess I’ll drop that hashmap lookup stuff and go back to float parsing. Knowing a little bit about single-precision floating-point format and the IEEE 754 standard I knew that wasn’t going to be easy to implement a fast enough version of float parsing. So I looked around for available crates and found fast_float. A quick change to our code :
let value = fast_float::parse(byte_value).unwrap();
Benchmarks of course:
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./target/release/naive |
250.4 ± 1.3 | 248.5 | 252.1 | 2.98 ± 0.11 |
./target/release/naive_hash |
206.6 ± 1.1 | 204.9 | 208.4 | 2.46 ± 0.09 |
./target/release/naive_hash_bytes |
115.8 ± 1.4 | 113.0 | 118.0 | 1.38 ± 0.05 |
./target/release/f32_parsing |
110.8 ± 2.3 | 105.1 | 114.6 | 1.32 ± 0.05 |
./target/release/ff32_parsing |
83.9 ± 2.9 | 80.0 | 97.4 | 1.00 |
That’s great ! ~3X speedup from our first version !
7. Optimize read_until
Let’s profile our code again:
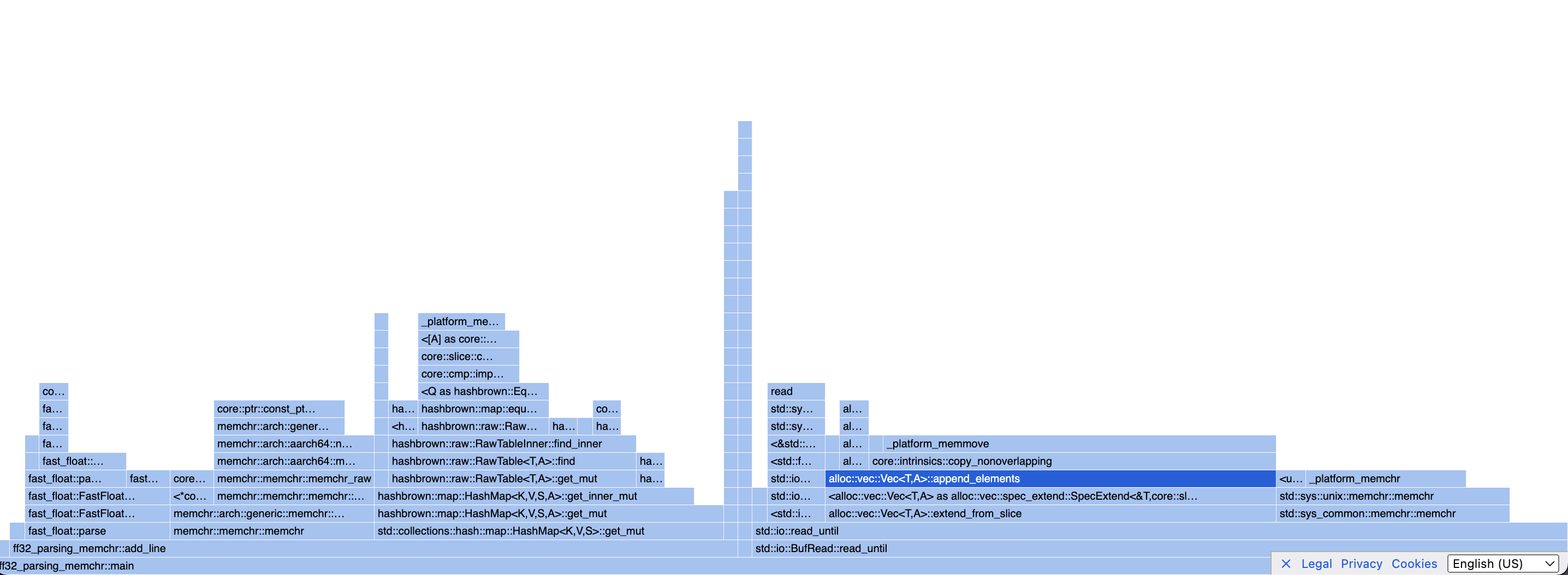
There it is again! That extend_from_slice looks crazy! We need a faster version. Looking again at the code we can see why:
fn read_until<R: BufRead + ?Sized>(r: &mut R, delim: u8, buf: &mut Vec<u8>) -> Result<usize> {
loop {
let (done, used) = {
let available = match r.fill_buf() {
// ...
};
match memchr::memchr(delim, available) {
Some(i) => {
buf.extend_from_slice(&available[..=i]);
(true, i + 1)
}
None => {
buf.extend_from_slice(available);
(false, available.len())
}
}
};
r.consume(used);
read += used;
if done || used == 0 {
return Ok(read);
}
}
}
The function calls extend_from_slice to fill the buf you gave with the line it parsed. The thing is why are we returning it? we could parse it in place and limit the call to extend to only happen for the part we didn’t process ie the remaining. In code it will be clearer:
fn parse_reader<R: Read>(mut reader: R) -> FxHashMap<Vec<u8>, Measurement> {
let mut records: FxHashMap<Vec<u8>, Measurement> = FxHashMap::default();
let mut buf = [0u8; 4096];
let mut remaining = Vec::with_capacity(1024);
while let Ok(n) = reader.read(&mut buf) {
if n == 0 {
break;
}
let mut start = 0;
// Append what was left in the previous iteration
if remaining.len() > 0 {
match memchr::memchr(b'\n', &buf[start..]) {
Some(pos) => {
remaining.extend_from_slice(&buf[start..start + pos]);
add_line(&mut records, &remaining);
remaining.clear();
start += pos + 1;
}
None => break,
}
}
// No extend here : That's a huge portion !
while let Some(pos) = memchr::memchr(b'\n', &buf[start..]) {
add_line(&mut records, &buf[start..start + pos]);
start += pos + 1;
}
// Copy what's left
remaining.extend_from_slice(&buf[start..])
}
add_line(&mut records, &remaining);
records
}
Hope it makes sense! You know it, benchmarking time:
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./target/release/naive |
235.5 ± 26.3 | 217.7 | 302.8 | 4.15 ± 0.67 |
./target/release/naive_hash |
209.2 ± 1.5 | 206.6 | 211.0 | 3.69 ± 0.43 |
./target/release/naive_hash_bytes |
117.4 ± 1.5 | 112.2 | 119.4 | 2.07 ± 0.24 |
./target/release/f32_parsing |
111.4 ± 2.0 | 106.7 | 114.6 | 1.96 ± 0.23 |
./target/release/ff32_parsing |
85.1 ± 1.3 | 82.8 | 87.3 | 1.50 ± 0.18 |
./target/release/ff32_parsing_memchr |
56.7 ± 6.7 | 54.2 | 92.1 | 1.00 |
Now we’re talking ! 4.15x speedup over the naive version
Looking at the profiler, 29% of the time is spent in float_pase and 20% in Hashmap::get_mut(). I don’t see how to optimize the get mut if not to rewrite my own Hashmap. But I reaaaally didn’t want to do that on a Thursday at 3 am !!
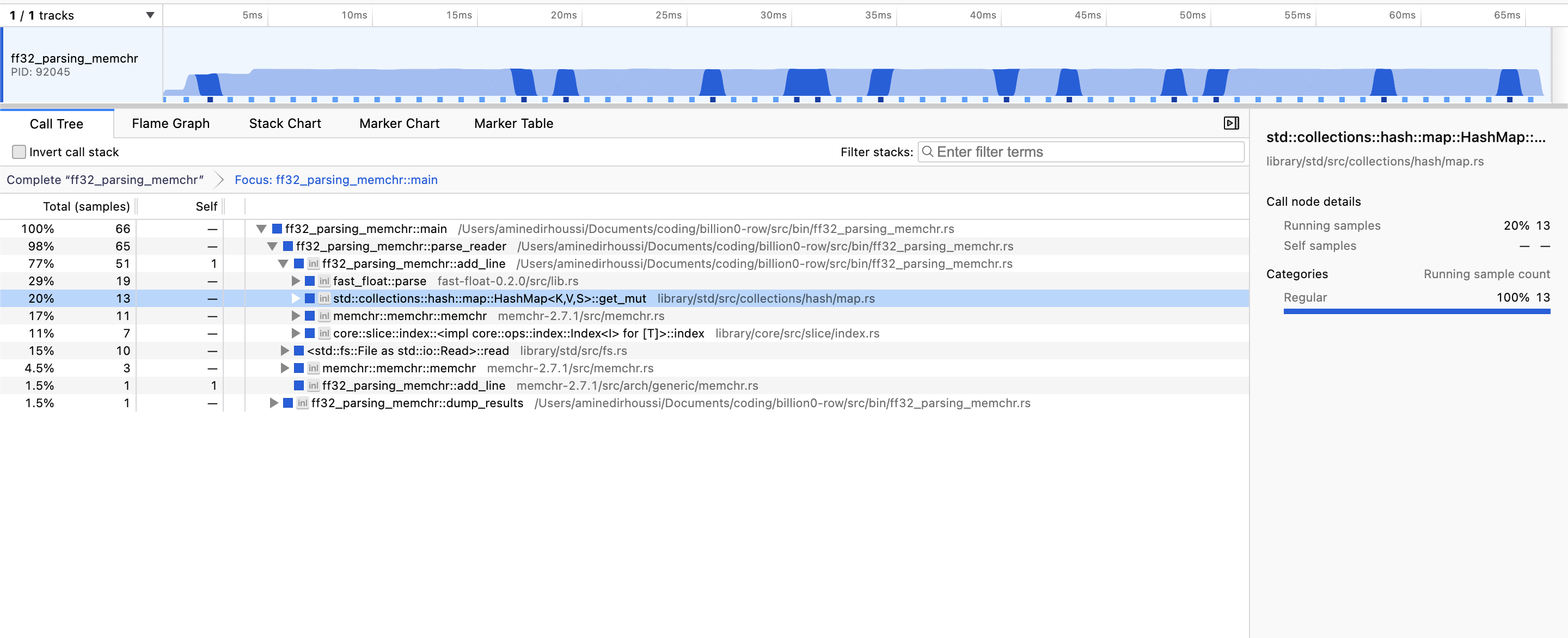
8. Finally, parallelism
Now the elephant in the room, multithreading! I want to focus first on optimizing single-core performance before turning it into multi-core, although it has its challenges, for this problem a map-reduce style algorithm is the obvious choice. The only bottleneck, I thought about is how to feed workers the bytes to parse. OS to the rescue! I can use mmap to map the file into memory and have a clean &[u8] representing the bytes and have the OS deal with reading the file into memory, evicting pages etc… It also has the nice property of eliminating syscalls when reading (although they didn’t appear on the benchmark).
Accessing the same file from multiple threads is one part of the equation, but how can each thread know what to work on 🤔 What I came up with is to spend the first portion of the code figuring out the proper chunking of the file given a set number of workers (threads), meaning chunking the file into equal part then looking the next break line starting from that block end, code will help I promise :
fn chunk_file(mmap: &[u8], file_size: u64, n_workers: usize) -> Vec<(usize, usize)> {
let chunk_size = file_size / n_workers as u64;
let mut chunks = Vec::new();
let mut start: usize = 0;
for _ in 0..n_workers - 1 {
let end = start + (chunk_size as usize);
match memchr::memchr(b'\n', &mmap[end..]) {
Some(pos) => {
chunks.push((start, end + pos));
start = end + pos + 1;
}
None => {
chunks.push((start, file_size as usize));
break;
}
}
}
chunks.push((start, file_size as usize));
// Figureout start and end of each range
chunks
}
Now the chunks represent a set of valid lines in the file. For the parallelism, I use rayon of course. A simple par_iter would process the chunks in parallel, then each processed chunk produces a Hashmap. The only thing left is to merge them into one which is the reduce part in map-reduce. Again rayon already provides a .reduce() method:
let records = chunks
.into_par_iter() // rayon magic here
.map(|c| parse_buffer(&mmap, c))
.reduce(
|| FxHashMap::with_capacity_and_hasher(500, Default::default()),
|mut left, right| {
merge_maps(&mut left, right);
left
},
);
The merge is straightforward:
fn merge_maps(left: &mut FxHashMap<Vec<u8>, Measurement>, right: FxHashMap<Vec<u8>, Measurement>) {
right.into_iter().for_each(|(key, val)| {
match left.get_mut(&key) {
Some(m) => m.merge(&val),
None => {
let _res = left.insert(key, val);
}
};
})
}
Finally, the benchmark:
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|---|---|---|---|---|
./target/release/naive |
251.4 ± 1.3 | 248.4 | 253.2 | 12.49 ± 4.23 |
./target/release/naive_hash |
207.8 ± 1.2 | 205.0 | 209.2 | 10.33 ± 3.50 |
./target/release/naive_hash_bytes |
118.3 ± 8.8 | 112.9 | 153.6 | 5.88 ± 2.04 |
./target/release/f32_parsing |
111.5 ± 1.8 | 107.6 | 114.8 | 5.54 ± 1.88 |
./target/release/ff32_parsing |
84.3 ± 1.7 | 80.3 | 87.2 | 4.19 ± 1.42 |
./target/release/ff32_parsing_memchr |
54.2 ± 0.3 | 53.4 | 54.9 | 2.69 ± 0.91 |
./target/release/ff32_parsing_memchr_par |
20.1 ± 6.8 | 13.0 | 58.4 | 1.00 |
Using 8 threads on my M1. I achieved a 12.5X speedup 🤩🤩!
Looking at the profile we can see that all we do is wait on the join method and do some allocations for the reduce part:

8. Coming back to SIMD
I felt that the SIMD route was very promising but felt a little bit janky. Dealing with the remaining chunk was not a great design, computing the positions had branches… So I set aside some time to focus on cleaning it up and giving it a shot.
Dealing with a remainder all the time was related to actually reading the file in chunks of 4Kb. Mmapping the file means getting a single reference to a &[u8] so there is no need to deal with this logic. I could directly iterate over the file with chunks of SIMD_LANE width and parse SIMD vectors from there. The remainder can be dealt with at the end using a slower code path.
// Here data == &*mmap;
fn parse_file_simd(data: &[u8]) -> FxHashMap<Vec<u8>, Measurement> {
// ...
let (chunks, _remainder) = data.as_chunks::<SIMD_LANES>();
// Chunks are processed using SIMD
// ...
}
I don’t know what I was thinking when I wrote the position computation code. Sorry that you had to see that code… I masked the original byte SIMD vector the used the mask to select from a simd_positions vector and iterate over the results to push it to some previously allocated vector of positions. Horrible! I sat down and thought about this part and the answer was pretty obvious! The mask already encodes information about all the b'\n' bytes, it’s there 1’s. All I need to do is find them. What I did was convert the mask to a u64 and count the number of right-side 0s this would give me the rightmost break line. Then I XOR the mask with offset to remove this position. That’s it! A little bit of coffee and binary arithmetic was all it took to clean up that mess
fn parse_file_simd(data: &[u8]) -> FxHashMap<Vec<u8>, Measurement> {
let mut records: FxHashMap<Vec<u8>, Measurement> = FxHashMap::default();
let end_line: Simd<u8, 32> = u8x32::splat(b'\n');
let (chunks, _remainder) = data.as_chunks::<SIMD_LANES>();
let mut start = 0;
for (global_idx, c) in chunks.iter().enumerate() {
let simd_buf = u8x32::from_slice(c);
let mut mask = simd_buf.simd_eq(end_line).to_bitmask();
// How many we found, this does a quick popcnt
for _ in 0..mask.count_ones() {
let pos = mask.trailing_zeros();
let global_pos = global_idx * SIMD_LANES + pos as usize;
// Remove the right-most 1 in the bit mask
add_line_simd(&mut records, &data[start..global_pos]);
start = global_pos;
mask ^= 1 << pos;
}
}
// TODO: deal with the rest of the chunk
records
}
In this moment of (rare) clear thinking, I had one thing dawned on me: there is no need to parse the values as floats! We only have one decimal, so I could have all the numbers an i32 and divide it by 10. So I rewrote the parsing:
#[inline(always)]
fn parse_val(data: &[u8]) -> i32 {
let mut start = 0;
let sign = match memchr::memchr(b'-', data) {
Some(_) => {
start = 1;
true
}
None => false,
};
match memchr::memchr(b'.', &data[start..]) {
Some(pos) => {
let (left, right) = unsafe { data[start..].split_at_unchecked(pos) };
let exponent =
left.iter()
.fold(0, |acc, &digit| acc * 10 + (digit & 0x0f) as u32) as i32;
let fraction = right[1..]
.iter()
.fold(0, |acc, &digit| acc * 10 + (digit & 0x0f) as u32)
as i32;
// One decimal
exponent * 10
+ fraction * {
if sign {
-1
} else {
1
}
}
}
None => {
let exponent = data[start..]
.iter()
.fold(0, |acc, &digit| acc * 10 + (digit & 0x0f) as u32)
as i32;
exponent * {
if sign {
-1
} else {
1
}
}
}
}
}
I know… it’s pretty messy, and sadly didn’t improve the benchmark :
Summary
'./target/release/ff32_parsing_memchr' ran
1.08 ± 0.06 times faster than './target/release/ff32_simd_mmap'
But hey, it was a shot worth taking and I learned some new tricks!
Summary
Looking at the flame graph of the latest implementation, I think that it was time to call it a day. I think that overall I have a pretty solid solution and I am not as qualified to do real micro-optimizations (that’s something I am trying to learn)! Here are the biggest takeaways :
- Changing the hash function: Duuh! I still feel it’s something that could be improved further. I’ll come back to this when I look at the brilliant solutions people posted.
- Moving from String to bytes: We should think twice about using Strings in contexts where performance is needed
- Measure first! : Always. I thought that my hashmap lookup trick to avoid float parsing was pretty slick. But it turns out that parsing was the way to go. Hashmap lookup probably caused some cache evictions, pointer chasing, etc whilst parsing in place skipped all that.
- RTFM! Also, you should probably look at the generated assembly and see if it matches your assumptions.
Looking at community solutions
Let’s first look at the C++ implementation, here are the main points the author discussed: Unsigned int overflow hashing: cheapest hash method possible.
- Unsigned int overflow hashing: cheapest hash method possible: This is probably the most important optimization. I didn’t know this technique but it seems to have a very big effect on performance. 🔴
- SIMD to find separator
;: I guess I am checking this box with the use ofmemchr✅ - SIMD hashing:
FxHashmapdoes use SIMD and hashes 8bytes at the time but I don’t know how it compares. 🔶 - SIMD for string comparison in hash table probing: Rust’s hashmap does SIMD lookup with quadratic probing. ✅
- Parse number as int instead of float: For me this didn’t seem to improve the performance that much. 🔶
- Use mmap for fast file reading: I don’t know about fast reading. Even with buffered reading syscall don’t pop up in the profiler. ✅
- Use multithreading for both parsing the file and aggregating the data ✅
The author also mentions:
- Notice properties of actual data
- 99% of station names have length <= 16, use compiler hint + implement SIMD for this specific case. If length > 16, use a fallback => still meet requirements of MAX_KEY_LENGTH = 100
- -99.9 <= temperature <= 99.9 guaranteed, use special code using this property
I guess getting some statistics about the data isn’t cheating but I don’t know if you would rely on that in the real world. For example getting heuristics about station uniqueness would help. One example is to see that all the stations’ names are present in the first 100_000 lines of the file. Maybe I am just hating because I didn’t think about that…
The rust implementation has a very detailed blog post about his process with some very interesting ideas:
- Ptr Hashing: Another hashing technique I knew nothing about. The author used his implementation. The basic idea is to reduce the Hashmap lookup by having a perfect hash function and then do some magic to spit out an integer < 512. Because the number of stations is less than 512 this works perfectly. I really should read more about hashmaps …
- A bunch of awesome micro-optimizations…
That’s it for me, hope you enjoyed your read! This challenge was a lot of fun and only feel motivated to learn more about the amazing world of performance-aware programming 🤩