Daskqueue: Dask-based distributed task queue
I started working on a distributed task queue library a few months back. Now, what is a distributed task queue library? Let’s say that you theoretically want to process a huge number of documents. Each document is composed of a variable number of pages. Processing each task takes a variable amount of time. This is a classic embarrassingly parallel workload. Each page can be processed in parallel as the processing does not impact in any way other tasks. Okay, that’s great and there is a boatload of libraries providing this exact functionality. You basically put the tasks in a queue and spawn workers to get tasks from it. Each worker receives work by getting an item (or multiple items) from the queue, working on it, and doing the process all over until no work is left.
Think of a worker as a single process running on some computer somewhere. This process has to communicate with a queue. Now hold onto your seat, the queue is ALSO a process. Boom, mind blown!
Okay, now that you have recovered, the queue can be either one or multiple processes. These processes can run on a single machine or multiple ones. This is what I mean by a distributed task queue.
Ok, why daskqueue? For those of you who don’t know Dask: Dask is an amazing library for parallel computing written entirely in Python. It is easy to install and offers both a high-level API wrapping common collections (arrays, bags, dataframes) and a low-level API for written custom code (Task graph with Delayed and Futures). Being written entirely in python, it is easily deployable on various architectural targets and integrates amazingly with the Pydata ecosystem. Looking at the data science library landscape, it has become quite obvious that Python has dominated the space, and running any Python function across a Dask cluster is really straightforward. Dask also provides the distributed library as a lightweight distributed computing library in Python. It extends both the concurrent.futuresand daskAPIs to moderate-sized clusters.
For all its greatness, Dask implements a central scheduler (basically a simple tornado event loop) involved in every decision, which can sometimes create a central bottleneck. This is a pretty serious limitation when trying to use Dask in high-throughput situations.
For the type of workload I described above, mapping a processing function on millions of tasks will bring the Dask scheduler to a halt. Batching work is an obvious solution here BUT remember that the processing time varies widely between task items. You could have a lot of idle workers waiting for a single worker to finish a batch of long-running tasks. Implementing work stealing at this level is quite difficult …
A task Queue is usually the best approach when trying to distribute millions of tasks. Implementing distributed system using queues is a common trade-off: trading the increased latency for improved throughput. This is where the daskqueue libraries come in (drop batman superhero music here) :
Daskqueue is a small python library built on top of Dask and Dask Distributed that implements a very lightweight Distributed Task Queue
As of now, you can simply pip-install it and start using it right away on your dask cluster:
pip install daskqueue
I also live-coded a large portion of this project on Twitch. You can follow me on my channel amindiro.
The whole project is open sourced on GitHub: amineDiro/daskqueue
Why would use Daskqueue?
Think of this library as a simpler version of Celery or Kafka built entirely on Dask. Deploying Celery on some environments (HPC environment for instance) is usually very tricky whereas spawning a Dask Cluster is a lot easier to manage, debug and clean up.
For those of you thinking: “Pff… Dask already provides a Queue implementation “, I would say yes, but they are mediated by the central scheduler. They are not ideal for sending large amounts of data (everything you send will be routed through a central point) and are limited by the scheduler throughput of 4000 tasks/s. I wrote the daskqueue python on top of Dask Actors to implement distributed queues. By building on top of Dask, we can abstract all the communication layers between actors which reduces daskqueue library code significantly and bypass the scheduler to implement a highly scalable task queue.
I also used Actors because:
- Actors are stateful (queues need to be stateful …) they can hold on to and mutate state. They are allowed to update their state in place, which is very useful when implementing queues or other stateful behavior!
- NO CENTRAL SCHEDULING NEEDED: Operations on actors do not inform the central scheduler, and so do not contribute to the 4000 task/second overhead. They also avoid an extra network hop and so have lower latencies.
- Actors can communicate between themselves in a P2P manner, which makes it pretty neat when having a huge number of queues and consumers.
Overall library architecture
Before diving head down into some implementation details, let’s first think together about the different agents in this system. The primary object in this system is a Task. The simplest way of viewing a task is a python function with some parameters. We assume that each task is self-describing, i.e it doesn’t need some context to be executed. The tasks need to be passed around and send back and forth between processes in a cluster, so we wrap them in a Message. This message will encapsulate the unit of work we need plus any other metadata we need to carry around between our actors (generation timestamps, delivery time ….).
Having defined the unit of communication, we need a set of queues where we put work and consumers to get it. The messages are sent to these queues and then popped by consumers to be consumed (duh !! ). Bare with me a second here, remark that these steps are decoupled! which means putting messages in a queue has nothing to do with consuming them at a later point. We’ll come back to this point in more depth in the implementation details section for queues.
Ok great, now we need some kind of managers for these objects. For example, we need to know how many queues we have, how do we route work to them and how consumers interact with some subset of them. Consumers also need to be managed. They need to be spawned across the cluster, and they need to be instructed to start fetching work, closed, and get their results back to our main process.
Designing distributed system entails thinking about failure modes, period. Let’s think together about what might happen. Consumers die unexpectedly, Queues could die. Focusing on the consumers, they could either stop while working on a task, before fetching the task, or at some other state we didn’t think about. To simplify let’s think of a simple happy world where we only have one queue and one consumer and where Simba’s dad didn’t die that sadly (seriously Disney, I was 5 for god’s sake !). This consumer could fetch work from the queue, then die unexpectedly. We would lose this task because we popped the messages from the queue and sent them to the consumers. The common way to handle this kind of system is to use an acknowledgment mechanism. I’ll refer to this as acking/unacking. The queue will hold on to the delivered message until the consumer acks it, which means we have the OK from the consumer to delete it now and then. Pushing this further, we can either ack a message when it is delivered (which means we can die and lose the task) if we don’t really care if all the tasks are executed, or we could ack each message separately at the end of the processing. Late acking induces performance hit because of the chattiness between the consumer and queue but is a tradeoff we need to make for the overall correctness of the system. So now we have a way to deliver messages that didn’t receive an ack if a certain period passed.
We also need some kind of way to introspect into these objects. We need to know how many tasks were processed, how many are pending across the queues, and how many failed. This kind of introspection is critical when debugging distributed systems. For instance, we can see if the tasks are uniformly distributed across the workers, we can also check that the tasks are correctly processed, etc….
I designed the daskqueue library to be simple. I don’t really like code clutter or complex abstraction just to satisfy some weird design pattern or some internal yearning for more code lines…That’s neither here nor there, here is an overview of the architecture :
Daskqueue overall architecture
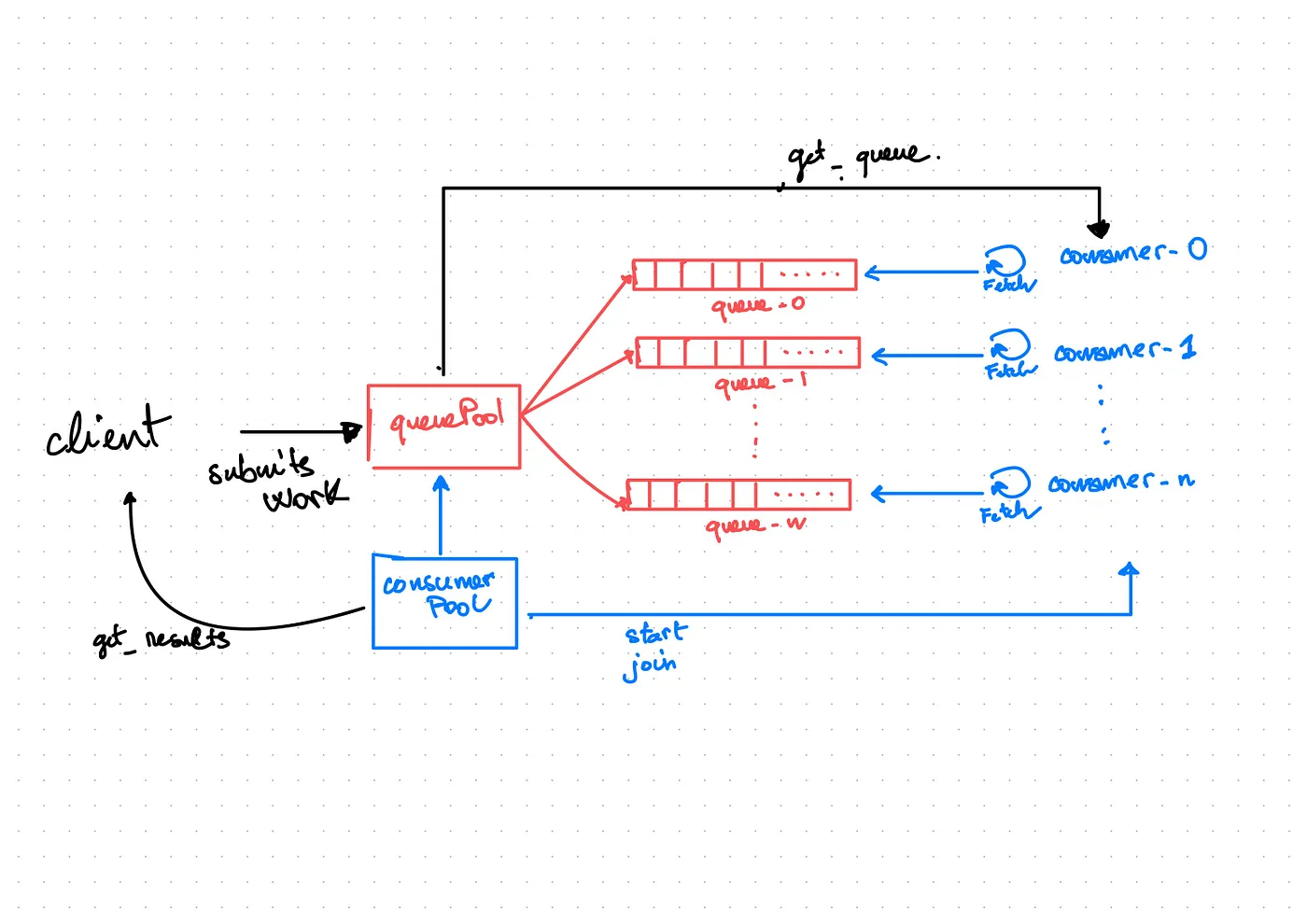
- The QueuePool manages n-queues actors
- ConsumerPool manages n-consumers actores
- The client schedules work by submitting tasks (also messages) to the QueuePool
- The QueuePool distributes work across the n queues using a simple round-robin
- The client starts the ConsumerPool
- The consumers request a queue from the QueuePool and attach to this queue for fetching work
- The consumers asynchronously fetch work and process them in the dask worker’s
ThreadPool. - The client can stop the Consumers by calling the
.join()method on ConsumerPool which polls the queue pool at regular intervals until all queues are empty
Implementation
QueuePool
- This is an interface for a
QueuePoolActor - It interfaces with the main process and the consumers.
- Submission to the queues is done either unitary or in batch style. The batches will simply be routed to the queues in a round-robin fashion
- It also holds a reference to queues and their sizes.
- Offers function to get an overview of the queues and the message
Queue:
Let’s go back to the decoupling discussion we started in the overview section. A queue holds and serves messages. Holding can mean a lot of things… It can basically range from: do we try holding it until the end of time, or do we hold it in volatile memory for 1 ms and then drop it if no one claims it? Ok, these may be extreme cases but what if I am designing a library and can think of anything I want? Daskqueue provides two types of queues: Durable queues and Transient ones. The durable queue will hold and serve the messages from the disk. Transient queues will serve them from memory. Messages in a transient queue would be lost in case of a restart or a queue actor failure but durable queues will restart at their previous state in case of a failure and will not lose the sent messages. Of course, you should think about the tradeoffs when using either type: the transient queues tend to be faster even though I tried to optimize the durable queue to provide good performance in most cases.
TransientQueue
- The default queue class.
- The submitted messages are appended to an in-memory FIFO queue. Basically, nothing to see here. I just wrapped the Queue class from the standard library in an Actor class and added some methods to put, get, and ack messages.
One note here is the addition of a special data structure to manage the delivered messages ( a sorted dictionary) to be able to reschedule unacked messages. The mechanism will be detailed in the durable queue section because I basically reused the same logic.
DurableQueue
This is a disk-backed queue for persisting messages. At first, I thought about using existing libraries to implement a disk-based queue, Projects like LiteQueue already offer a queue like interface to a sqlite database. This is great but first I didn’t want to add dependencies to the library and something like SQLite is great but I didn’t necessarily want a full-on ACID transactions backend all the hoopla for a simple disk queue. I also wanted this part to be fast enough to be usable!
I drew this schema with the overall logic for the durable queue, don’t worry I’ll break down each portion of the schema below.
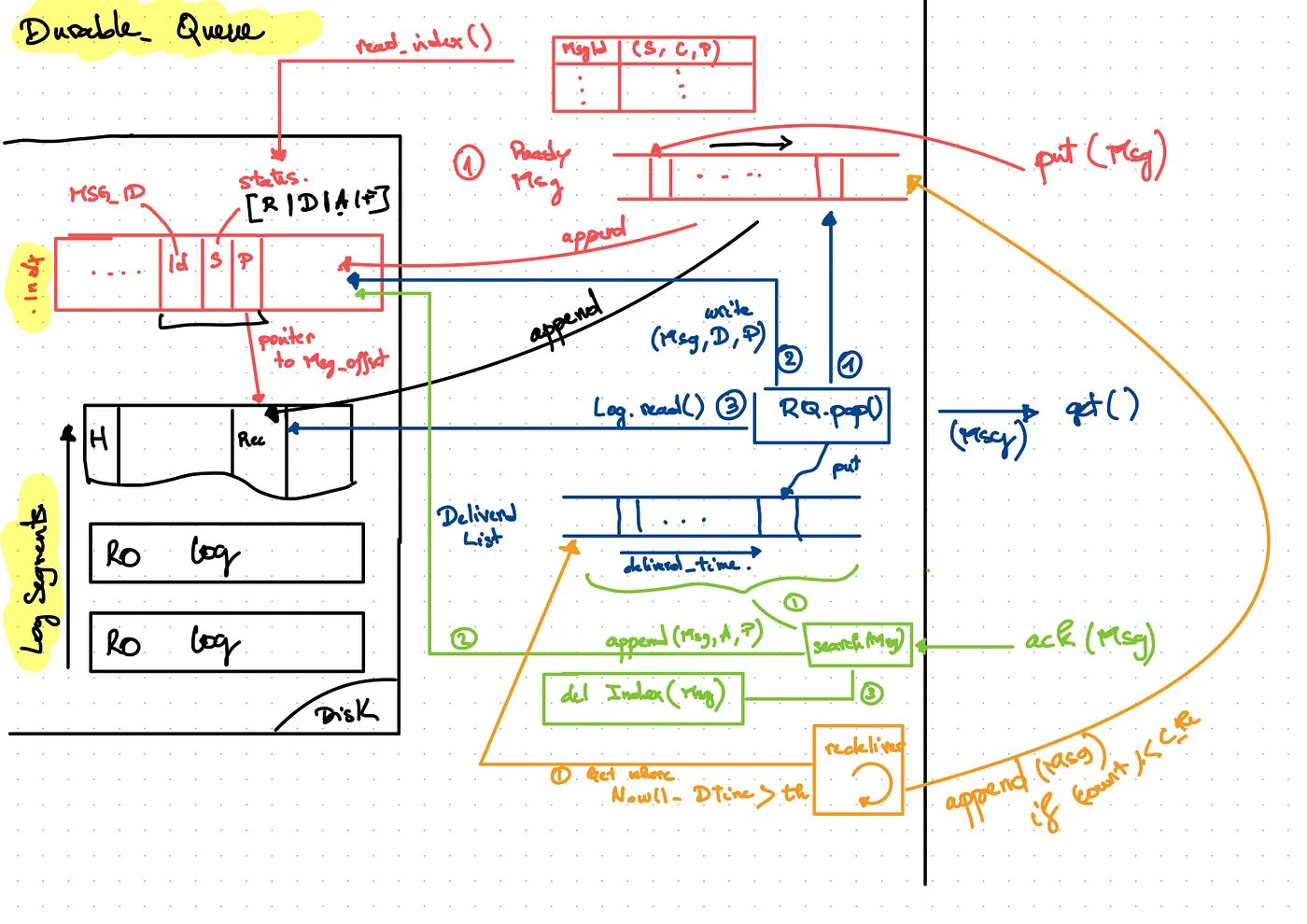
DurableQueue interface and underlying objects
The bare minimum requirement for durability is to write messages to disk, then read them back. OK great, KV stores have been doing this since the 14th century BC, but again I wanted to write a custom storage layer because it minimizes third-party dependencies, and let’s be real here, it’s a lot of fun to build it yourself as a side project!
Before explaining the design choice let’s get a quick lesson in persistence storage fundamentals:
- When working with disk IO, avoid random IO as much as possible, even with SSD where Read IO is not as bad as HDD, we still see a considerable performance gain when we either read sequentially or write sequentially.
- Reading and Writing to disk are done via system calls, which means the OS is responsible for the actual writing to the underlying hardware, bytes are copied from user space (where your app lives) to kernel space ( where the OS lives) and then a call to who knows how many layers is done before the bytes reach your device.
- The disk is only accessed in block chunks, typically a block size of 4 KB. This means that writing a single byte is not possible. You can only read/write multiples of a block size at a time. All modern operating system kernels implement a complex layer of caching, buffering, and I/O management between devices and application to abstract this complexity and offers simple
write()andread()syscalls with a bunch of flags. - The OS offers a special system call :
mmap(). We ask the kernel to map some bytes of a file represented by the file descriptor (think of an integer that points to a file) into memory. Why would you do that you say? Well, reading from and writing to a memory-mapped file does not incur any system call or context switch overhead, it also minimizes copying of buffer between the OS (kernel space) and your application (user space). It also handles complex caching and flushing of memory pages to the underlying storage so you don’t have to think about buffering, cache eviction policy, flushing, etc … Memory mapping comes with its downsides, especially in the multi-read/multi-write application. Writing and reading from disk will only be done in one thread in daskqueue so we don’t have to worry about this.
Coming back to the schema, I matched colors with the core functionalities a durable queue has to offer. Adjacently, we need to have some disk and in-memory data structure to support the system :
(RED) PUT message:
Again, we need to put messages in the durable queue. Messages come sequentially, so we can create a file, open it, serialize the message ( convert them to bytes) and write them sequentially to a file, one message at a time. I’ll come back to the serialization in the performance section, but python objects are easily serializable using pickle protocol. This kind of append-only writing is very efficient and used in many systems like LSMTree-based indexes in databases, and Log structured file systems … This is why I called this file a LogSegment. LogSegments have a fixed size, this is a minor detail to reduce single file sizes and avoid bloat. We append to a file, close it when we reach its maximum size, put it in a read-only mode, and open a new one. Great, this way is pretty easy!
Wait, wait… At some point, somebody will ask you to give them the messages. Our system delivers the messages in FIFO style. So we need to go back, read the LogSegment file, deserialize the message, and send it. But wait ? How do we know where the first undelivered message is 🤔 Ok so we don’t just write the data, we also need some kind of pointer to where the messages are, we need to make sure that this pointer is persisted in case we have a failure. This is what an index is! This index needs to be maintained both on-disk and in memory. There are many types of indexes but the common ones are B+Trees, LSM trees, and Hash Tables. Hash tables are pretty easy to implement, and there is a trick to leverage the append-only mode. I implemented the IndexSegment as a combination of a bitcask index for segment offsets and a WAL file: it is an append-only file where we record message status after each queue operation (ready, delivered, acked, and failed) and an offset to the message in one of the LogSegments. After a restart, we read the index sequentially and update the in-memory data structures to reconstruct the pending and delivered messages. This is very easy to implement and offers a clean interface for retrieving messages.
For each message we do the following :
- Serialize the message
- Append it to the LogSegment
- Compute a checksum of the :
checksum = crc32(<MSG_SIZE><MSG>) - Write
<checksum><msg_size><msg><_FOOTER>. The**_FOOTER**is needed to find the latest written message when we reopen the LogSegment. - Get the Msg offset : (file_no, offset in the file)
- Pack the message into an index record to write to disk :
<CRC-4><TIMESTAMP><MSG_ID><STATUS=READY><MSG-POINTER>. - Push the index_record into the
readyordered dictionary.
(BLUE) GET message:
Now that we have our IndexSegment and LogSegments, delivering messages is pretty easy :
- Pop the messages from the
ready. - Get the record offset
- Read the record from the disk. We check data validity with the checksum and read size bytes.
- Deserialize message
We need to stop and think here. Remember that ack mechanism we discussed earlier? We actually need to maintain different message statuses to redeliver unacked messages. To do so, we need to keep an in-memory index of delivered messages. We don’t need any additional structure to maintain persistence because of how our index works. Think about it! we only need to append the same index record to the IndexSegment with a different Status we will read the whole index and update the in-memory data structures as needed. At the restart, the delivered message index record will be read after the ready one, so we call the same update function to replay history: pop it from ready and push it to the delivered, pretty neat!
- Pack the message into an index record to write to disk:
<CRC-4><TIMESTAMP><MSG_ID><STATUS=DELIVERED><MSG-POINTER>. - Put the index record in
delivereddata structure.
(GREEN) ACK message:
Acking is also very similar to the get message method. We basically repeat the same steps with a slight modification in message status:
- Pop message from the
delivereddata structure. One note here is that we need an efficient way to retrieve acked messages while retraining an order for delivered messages. This is why I used a SortedDict as the sorted data structure to maintain delivered messages sorted by delivery time. We can efficiently retrieve the acked message by using the delivery_timestamp attribute. - Create an index record where the message status is ACKED.
- Write the index record to the IndexSegment.
(ORANGE) REQUEUE message:
As we detailed above, unacked messages need to be re-queued. This is where the sorted data structure comes in handy. Because the delivered messages are sorted by delivery time, we can easily slice into them and get those where the time.now()- delivery_timestamp exceed some time delta.
A background thread loops indefinitely and does the following:
- Get current timestamp
- Filter
deliveredmessages based on the delivered timestamp - Update messages status
- Move the message to
ready - Sleep some amount of time
We are done! Of course, there are some shortcomings in this implementation and some things that need to be upgraded. I’ll be more than happy to hear your suggestions about further improvements. One thing that bothers me, is having these separate in-memory data structures that we need to update in addition to the log files.
There is also the question of garbage collection (or compaction). At some point in time, we will need to clean the index file from all the garbage message records. I’ll come back to this in the limitations section.
Consumers
All consumers inherit from a ConsummerBaseClass . This core class implements all the core logic for Consumer actors to interact with the queue pool, fetch tasks and process the. You can extend the daskqueue library by implementing your own ConsumerClass with special logic, you’ll just need to define a concrete def process_item(self,message: Message) method that will be run for each fetched message. I’ll skip all the boring detail and concentrate on the core workflow.
- Consumers pull messages: all consumers have a
start()method. At the start, the consumer contacts the QueuePool to get an assigned queue. The queue pool cycles over its queues and sends a queue actor object to the consumer. This extra step is done to avoid a central bottleneck where all queues retrieve items for a single manager. You can basically scale the number of queues and the number of consumers independently ( keep in mind that for now: nb consumers ≥ nb queues). This is also useful to avoid queue contention, data is sharded across queues, and each consumer consumes from a single queue ( at least for version 0.2.0). - Async infinite fetch loop: each consumer runs an infinite fetch loop to pop items from the queue assigned by QueuePool. Consumers will get items in
bath_sizeto avoid multiple calls to the queue. - The Consumer will then schedule
process_itemon the Dask worker’s ThreadPool, freeing the worker’s event loop to communicate with the scheduler, and fetch tasks asynchronously… - I also implemented a baked-in rate limiting feature: the consumer will not fetch more than
max_concurrencyitems. This is pretty useful and serves as a back pressure mechanism to avoid swarming the thread pool with a lot of work. - Consumers can be canceled: consumers will gracefully shut down by first stopping the fetch loop and waiting until all running tasks in the thread pool are done before exiting.
Benchmarks: queue throughput
I tested the throughput on a 2020 M1 MacBook air with 256GB SSD and 16GB of RAM. I submitted 10 000 tasks of a simple No-op function in a batch fashion. I also used batching in consumers to improve system latency.
Transient queues
For a cluster of 1 queue, 1 consumer:
- Mean write ops 72486.79 wop/s
- Mean read ops 9753.57 rop/s
For a cluster of 4 queues, 4 consumers:
- Mean write ops 94196.81 wop/s
- Mean read ops 23921.28 rop/s
Durable queues
For a cluster of 1 queue, 1 consumer:
- Mean write ops 66155.67 wop/s
- Mean read ops 8487.61 rop/s
For a cluster of 4 queues, 4 consumers:
- Mean write ops 83950.72 wop/s
- Mean read ops 18305.17 rop/s
Not bad for a pure python library! We can clearly see a near-linear speedup when using 4x more consumers in both cases. We can also see that the performance between the durable queues is not that bad! The truth is that for 10 000 messages we only serve messages from cached pages in memory anyway and we flush to disk asynchronously 😸
Limitations
As for the limitation, given the current implementation, you should be mindful of the following (this list will be updated regularly in Github):
Consumer limitations:
- We run the tasks in the worker’s ThreadPool, and we inherit all the limitations that the standard
dask.submit()method has. - A task that requires multiprocessing/multithreading within a worker cannot be scheduled at the time. This is also true for dask tasks.
- Doesn’t have a work-stealing mechanism yet. The consumer will keep asking the queue for work even when it’s empty. Work stealing could be implemented this way: we could switch to a different queue after X number of retries, and keep switching if the queue is empty 🤔
Queue limitations:
- The QueuePool implements simple scheduling on put and get. More sophisticated scheduling could be implemented in the future.
- QueuePool is a single point of failure… I was thinking about implementing a raft protocol between queue pool instances.
- Queues don’t implement replication. Messages routed to a queue will only be written to disk by that queue.
- Batch operation on queues run in the Eventloop for now at least, we can move this logic to run in the thread pool to avoid blocking operations on the event loop.
- Message serialization is a real performance bottleneck. The throughput could be 20–30X faster if we only send raw bytes… but we do need to serialize python objects (tasks are python functions). I used the
Picklelibrary as a default and fallbackCloudPickleif the task cannot be serialized by the former lib. CloudPickle is painfully slow …. - Durable Queues are not garbage collected. We keep all LogSegment even when all messages are consumed. The IndexSegment will also keep growing. This is a quick fix, we could just lock the writing, write all the in-memory data structures to a new IndexSegment and delete the old one. For LogSegment we could traverse the RO (old) LogSegments and write them to the active one, then delete them.
Contribution
Contributions are what make the open-source community such an amazing place to learn, inspire, and create. This project is still in its baby stages! Any contributions you make will benefit everybody else and are greatly appreciated 😍 😍 ! There is still a lot of work to be done
You can put all questions/bugs/ enhancements ideas on the project’s GitHub page: