Semantic search powered by WASM and WebGPU
A few months ago, I attended a Rust meet-up presentation focused on webassembly presented by the French startup Rayon. I read a little about the technology and watched two or three talk about it. Coincidentally, I also took an interest in the new wgpu graphic API presented by Google a little bit over 7 months ago, the API was particularly interesting to me because they introduced compute shaders. This new addition would finally mean having true cross-platform GPU kernels that can run on multiple platforms written in one shading language WGSL.
Reading about something is great and all, but nothing beats first-hand experience, I wanted to find an interesting enough project that I use wasm and wgpu. Having developed and deployed on multiple ML-backed services and pipelines, one recurrent problem kept nagging at me: model hosting. In a lot of cases, I found myself having to juggle the deployment of multiple models on a finite set of machines with a finite set of GPUs. Time slotting isn’t great if the model doesn’t all fit in VRAM. Even if all models could fit into the GPUs, managing inference requests is a nightmare. Dynamically loading and unloading models is not a great option either, especially for latency-sensitive applications due to the cost of reading the model from disk to memory, and then from memory to the GPU. So this got me thinking: what if we didn’t do the inference server side? Most consumer hardware is scary fast these days and heavily underutilized. We had to wait for `ggerganov` for the whole data science community to understand that you don’t need a 1 TB ram machine with 8-A100 to do model inference… But I digress.
Well, that seems like the perfect use case for a rust-basedwebassembly module! Model inference is a compute-intensive task that is preferably unloaded to the GPU.
A few weeks later I pushed the first version of
docVec: a client-side semantic search engine, running rust in a having the model run ENTIRELY on the client machine.
I started by setting some goals for the project were :
- Use Rust for ML inference: Rust binding for
torchandtensorflowhave existed for quite a while now but rust-based deep learning frameworks are been popping up lately, for instance, I have used the new shinningcandlecrate by Huggingface to implement a transformer model as a learning exercise and like it! - Use the GPU for model inference: Starting the project I wanted to see how attainable this goal was. WASM being quite young there wasn’t a lot of support for browser-based GPU inference but I’ll come back to this in more detail.
- Implement the search logic in a Webassembly module in Rust: The goal here is to understand some internals of wasm and its limitations. Also, I won’t overcomplicate the search engine, details in the next chapter, I promise.
- Keep the JS to a minimum: ML inference in javascript is possible using libraries like tfjs, but the goal is to keep the JS code to a minimum and define clean, low overhead boundaries between JS and the WASM module
- No bundler: JS tooling scares me a lot.. so I didn’t want any overcomplicated framework, bundler, or other over-engineered-1-month-old JS tool ….
Wth is semantic search anyway?
I think the search part is pretty clear in “semantic search”. Traditionally, text search is usually done using some kind of exact matching or fuzzy matching algorithm with some sprinkled clever pre/post processing techniques like stemming, and lemmatization… All it can do is to check, at scale, whether a query matches some text and return the result. The big downside of this kind of search is that you can’t match “meaning”, concepts, or context. This is where vector search comes in! Semantic search uses a vectorized (think a list of numbers) representation of your corpus. These vectors are constructed in such a way that similar content in meaning is closest in some metric on the vector space (commonly referred to as the embedding space). Now looking for a similar content means running the same processing on the query data to get its vector representation, then looking for the closest vectors and returning the matching text from the corpus. That’s it!
Now how can we generate those vectors? This is where neural networks come in. Generating a vector representation of your text can be done by a plethora of techniques. In the past simple classical techniques like BoW or TF-IDF could be used to represent text. These techniques fail to capture the richness and complexity of textual data and generate less than-optimal embeddings. Newer transformer-based language models can be used to retrieve a good representation of your data. For example, encoder-only transformers have a hidden representation of the input (these vectors here) which is exactly what we’re after!
Great, now that we have the basics in mind, here are the building blocks for semantic search:
- A way to generate embeddings: fortunately for us, Huggingface maintains a leaderboard of open and closed source models on the MTEB challenge. We can choose a well-performing, small enough model for the embedding task. I went with gte-small a small but good enough model that weighs 133MB and generates 384-dim embedding.
- How to run the embedding model: remember we are in WASM land here, in the next section I’ll break down the different choices that we have available given my (kinda arbitrary) requirements that I specified earlier.
- A way to preprocess text to feed to the model: again thank huggingface, without diving into the details in this blog post, we can use the
tokenizerslibrary to preprocess our input. Small caveat, because we are compiling to WASM, the defaulttokenizerscrate will not work. However, the crate has a special compiler flagunstable_wasmwhich makes it possible to use it in our WASM project. Neat! - A way to search for neighbors: remember I talked about vector comparison and returning matches. The comparison part is really easy, I’ll do a simple L2 distance between the query vector and the corpus vectors and sort them. Then we can easily return the k-nearest ones. This brute force approach will not work for a large corpus. Techniques like ANN with IVF or HNSW indexes are the way to go. For this use case, this approach will suffice as we are indexing a single HTML page with a few hundred text elements at the most.
Rust and WASM
This was by far the easiest project setup ever. Between the amazing Rust 🦀 and WebAssembly 🕸 book, the wasm-bindgen for generating javascript bindings, and wasm-pack for compiling the rust lib to the WebAssembly module, it took me 30min at most to read the book and set up the project. Keep in mind that I am a slow reader. Easy peasy! The only notable tweaks I made from the wasm-game-of-life template project are:
- Not using a bundler at all because I have js tooling PTSD ( I think that it is a real thing, google it).
- Adding a Rust build flag for unstable APIs because
WebGPU APIs are still unstable in web_sys
RUSTFLAGS=--cfg=web\_sys\_unstable\_apis wasm-pack build \\
\-d pkg \\
\--target web \\
\--no-typescript
Now to the meaty part: GPU-accelerated embedding generation.
Generate embedding
Doing GPU-accelerated inference on the web was a lot less mature than I expected. Thinking about it, the inference is either considered a backend task and you could use any shiny library you want, or a client-side one but usually on a resource-constrained environment like embedded devices. There you have frameworks that go straight to the metal or leverage on-chip hardware to do the inference. Browsers are weird because they are a middle ground between the two where you are basically at the mercy of the browser to provide you a way to securely access the host resources for computing. As of December 2023, here are the available methods for running model inference on the web that I gathered:
- Forget the GPU, CPU only:
- That would be a no-no for me, where is the fun in that? In all seriousness, you could compile a Rust framework to WAM and run it in the browser. WASM overhead would slow down inference of course and yes you couldn’t really leverage hardware acceleration like SIMD … but It would still work.
- If it wasn’t for the browser, I think that one solution is the Wasi-NN proposal for WASI-compatible runtime.
wasi-nnis designed to make it easy to use existing model formats as-is and access the host’s hardware directly. Talking to recently met amazing developer who uses it for his project, it seems that GPU acceleration is available for pytorch models and works for computer vision models. This would be great for our use case but enough dreaming, let’s get back to reality…
- We want that sweet GPU acceleration:
- Run inference on the JS side: using something like
tfjsa WebGPU accelerated backend. No fun, on to the next! - Burn (wgpu): Burn is a cool Rust-based deep learning framework. It supports multiple backends and
wgpuis one of them. Take a look at the coolwgpuMNIST demo here. This would have been great if I wanted to deploy a model that I have developed usingburnbut this is not the case. I want to import a pre-trained embedding model.burnsupports loadingonnxmodels by running a build time script to generate rust code that describes the models while converting the weights to burn native format. But that just seems wrong…. why go from a standard likeonnxto code generation to burn to do the inference? Also, I tried it and it didn’t work for the transformer-based models… - Apache TVM: The Apache TVM project embodies everything great and everything wrong about the data science world all at once. It is an end-to-end machine-learning compiler framework for CPUs, GPUs, and accelerators. Yeah, that’s what happens when compiler engineers get involved in data science! Great, so what’s the holdup? I think those engineers got a memo saying that data scientists only use Python and notebooks. So they went out of their way to generate badly designed Python bindings for the C++ library and provide huge unreadable notebooks showing how to use them. That’s a shame, it is an amazing project and probably the most advanced one to solve the cross-platform optimized inference but it is so complicated that nobody uses it
- wonnx: Finally what I was looking for! Take a look at the project’s about: ”A WebGPU-accelerated ONNX inference run-time written 100% in Rust, ready for native and the web.” Now we’re talking! All I have to do is load the model and …. Oh no it doesn’t work! Mmmm, let the fun begin.
The first issue was in the onnx model format itself, using the CLI from the project we can run nnx info model.onnx and take a look at the description (you can also use www.netron.app)..)
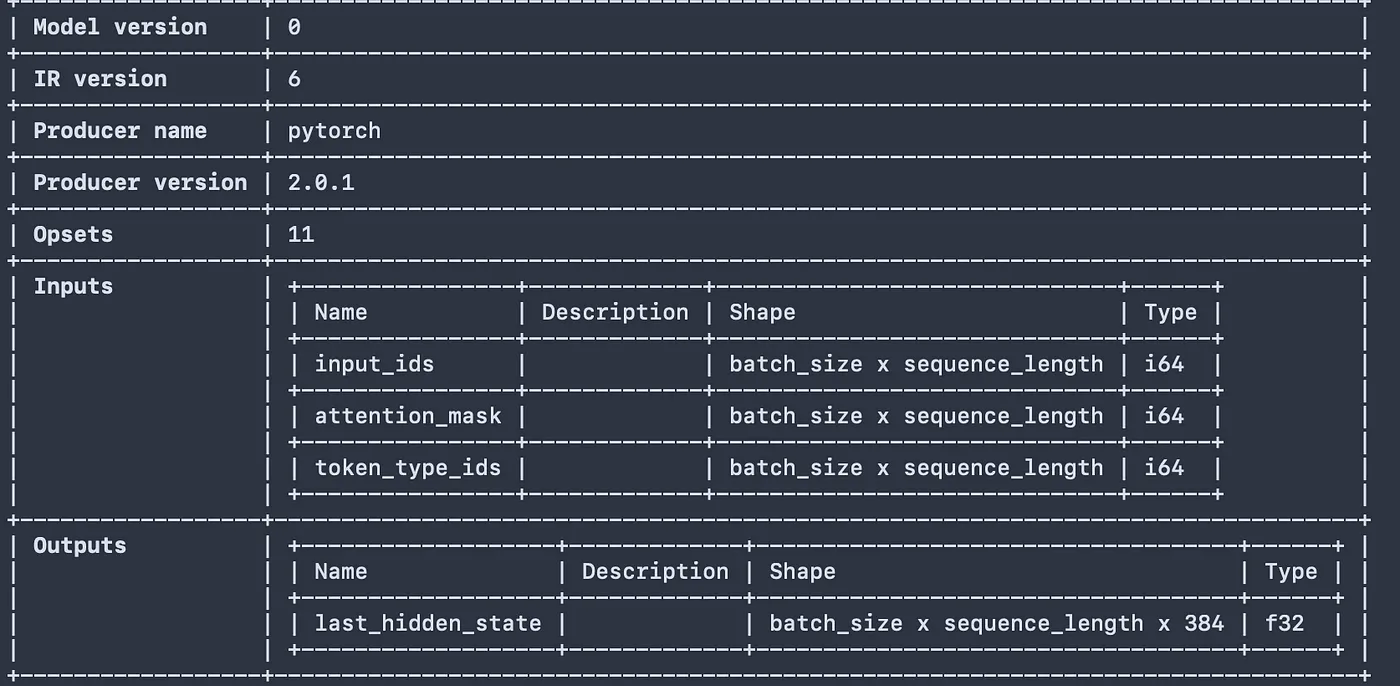
wonnx clearly states:
WONNX needs to know the shape of input and output tensors for each operation in order to generate shader code for executing it..
The first step is to modify the file to set input/ output shapes. At the same time, we can also simplify it. ONNX is great and all but too complicated. I used onnx-simplifier to do both steps at the same time. The gte-small model takes a maximum input length of 512, so I set sequence_length=512. and because we’ll only do one query search at a time, I set the batch_size=1 and called it a day.
Does the inference work now? not really … See setting input shapes means also inferring the shapes of each operator in our onnx graph. Unfortunately, some operators in our model graph don’t support shape inference yet. More precisely, wonnx doesn’t provide shape inference for the MatMul operator. But that’s a future me problem, so I ran the conversion as is without shape inference and generated a sim_model.onnx.
Hello there, this is future me and now I need to solve the MatMul issue. The exact error I was getting is related to the broadcasting rules for MatMul. For instance, running the inference as with the simplified model panics with :
UnimplementedVariant { variant:
"broadcasting for two stacks of matrixes
left side has shape 1x512x384:f32,
right side has shape 384x384:f32)
op: "MatMul"}
Ok, so the wonnx didn’t seem to implement the full numpy-compatible Matmul broadcasting rules. But thanks to the help of the project maintainers I am on the track to implement it and I am working hard also to improve the MatMul kernel performance. But a simple hack for now a least, is to notice that we only have a batch of 1. This means that we can cast view the 384x384 matrix as an equivalent to a 1x384x384 tensor without breaking the Matmul operation as wonnx supports multiplying two tensors with the same dim shape. The only thing to do is comment out the code that checks tensor sizes for broadcasting and append extend the right tensor dim by 1!
As a small aside kudos to the wonnx developers, it was a breeze to read and contribute to the code base. No weird abstractions or non-sensical interfaces that add performance overhead, it was clear and simple. All onnx does is read the model, match the node, compile its shader, run the graph through the optimizer, and run the inference!
Great! Matmul works, the next missing piece is one operator that was not implemented yet in wonnx. The gte-small model uses GeLu activation function which uses the Erf operator (for onnx opset <20). I took a little bit of time to learn the WGSL Compute shader which was very straightforward. I have some experience with writing Cuda kernels and the workgroup logic was basically the same. I opened a PR pending for merge :)
Finally! Inference is working! I can load the model and the tokenizer and embed arbitrary strings. Well, one last last last step was to write a mean pooling layer to average across the 512 dims (onnx output had the shape 1x512x384). Note also that because the input’s sequence length is fixed, the tokenizers add a max_length padding so I use the attention_mask to mask of the padded data from the final mean pooling.
Generating Index
Recall that the goal is pretty straightforward. Have a WASM module loaded on a web page to do a semantic search on the page. To get large enough web pages I used the Wikipedia Python API and downloaded the text of the “Python programming language” page. I used a special flag to get a simplified version of the page akin to what a browser reader would produce. I thought about dynamically generating the index from the Rust side and I would probably still do so soon but for now I have a parsed simple HTML page so I built the index in Python and loaded it in Rust. Here are the steps :
- Get the “Python_(programming_language)” Wikipedia page using the API
- Clean up the text and use a recursive text splitter to get text chunks of length 200 with overlapping 20 characters.
- Use the
sentencetransformerspython package to embed the corpus using thegte-smallmodel of course.
Great! Now we have our text corpus and its embeddings, but how do we load them in Rust ?? I thought about using a common serialization format like JSON to dump the index and load it from wasm but that was overkill. I also didn’t want to add the serde crate to my dependencies for something this small that I’ll use one time. So I decided to :
- Write each chunk in a .txt file with a line break
- Dump the embeddings as a contiguous buffer
data = embeddings.flatten().tolist()
buffer = struct.pack(f"<{len(data)}f", \*data) # little endian here
with open("../data/index\_embedding.bin", "wb") as f:
f.write(buffer)
I could include the raw bytes at compile time in the WASM module and load the Index for the Rust side:
static INDEX\_CONTENT: &'static str = include\_str!("../data/index\_content.txt");
static INDEX\_EMBEDDINGS: &'static \[u8\] = include\_bytes!("../data/index\_embedding.bin");
pub struct Index {
pub content: Vec<String>,
pub embeddings: Vec<f32>,
}
Here is a drawing to illustrate what we have so far:
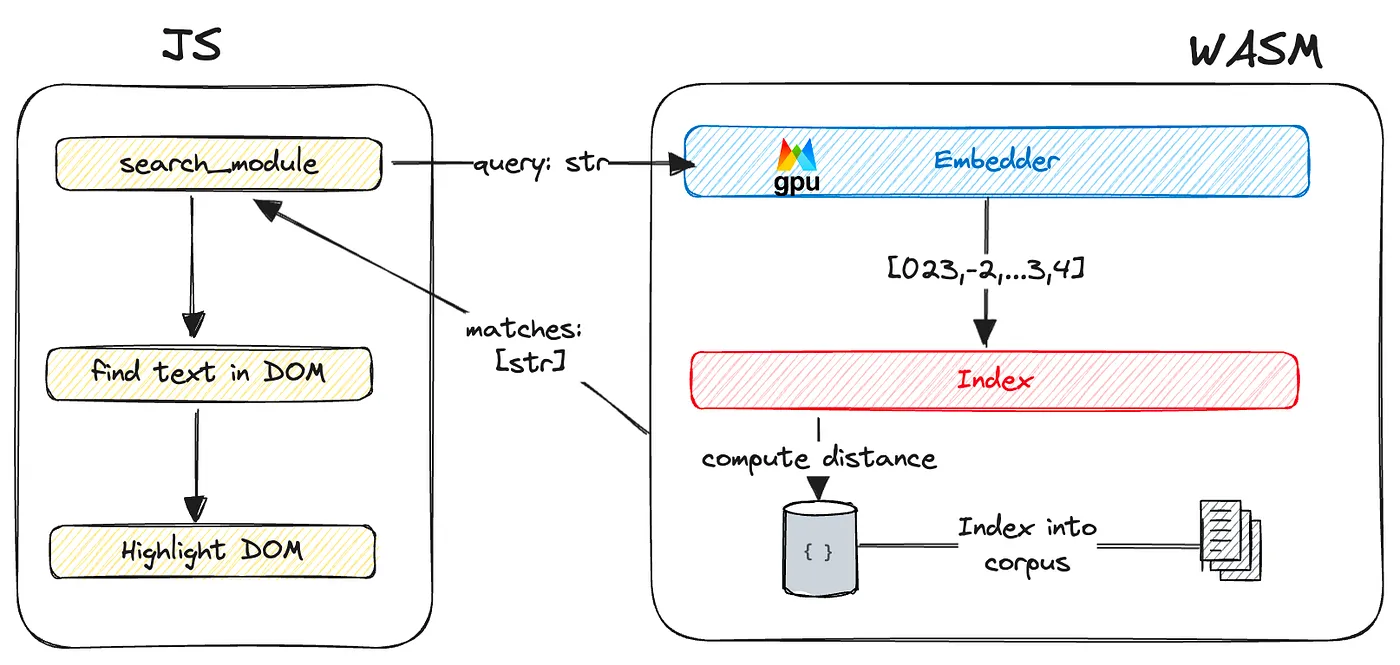
The frontend aka the less glorious
To be quite honest I have very limited experience with frontend development and don’t like it that much due to the insane amount of APIs, frameworks, and specifications to do simple things. This project just added a little more to this view I have…
Here is the current flow to make this work from HTML to javascript to Rust and back:
- At startup, I load the wasm search module which loads the embedder model sets up the wonnx session, and loads the index.
- I have an input text with a button, the user types his query there and clicks on the search button
- On click events: I call the search method with the provided query string and how many neighbors we want the search to return
- The search module calls the embedded, gets the embedding, and then calls the index. The index returns the k-nearest text chunks from our corpus.
- Now that’s the part I am less proud of, sadly matching arbitrary text in the DOM is a lot harder than I imagined and it wasn’t my focus for this project anyway. So talking with some friends with a lot more experience in frontend dev I settled on traversing the DOM and finding if the text is within the element’s text. If it is I’ll change the element style to highlight it. The highlight opacity depends on the distance ranking returned but the search module.
That’s it for me! I leave you with the full working docVec project:
You can see that we are finding elements that match on meaning: searching for “scientific computing” returns text that mentions the use of Python libraries for science stuff, etc…
What I have learned
This project took a lot of tinkering around to have a working example. The goal again was for me to build something using WASM in Rust and explore the WGPU library and I think I have learned quite a bit! Here are some final thoughts I have about these libraries and the overall usage of Webassembly for ML:
- I think that ML in WASM is a very good use case for the technology. Inference is a pretty compute-heavy task and is best implemented in low-level languages. Also, ML modules offer very clean interfaces to interact with JS, keeping a clean separated state and a well-defined API between the two. IMO, the only issue I think is the maturity of the ecosystem which is due to several factors: WASM being quite new, data science being a Python-focused domain and the GPU interfaces being a mess all around.
wgpucame into this segmented space to offer a single cross-platform solution but it will take some time to port ML frameworks to it. - wonnx is a great project! The roadblocks I faced were merely a fact that the project was quite early in his life. The provided examples were mainly computer vision models, and I used a (semi-) complex transformer model for this project. I think that model support will improve in the future. Another area I would love to contribute to is optimizing
wgpukernels. I don’t think thatwgpuwill be quite as fast as CUDA. Mainly,wgputries to be as high level as possible to truly target multiple platforms and it does so by basically transpiling the shader to underlying GPU libraries (Metal, Vulkan, DirectX…). These graphics APIs usually don’t provide you a way to use all your hardware capabilities for now at least. For example, I don’t think it is possible to use Nvidia Tensor Cores from Vulkan …. - The final wasm module weighs around 138MB The choice I made is to embed the all data into the wasm module which bloats it up. The model accounts for 135MB alone and the rest is the tokenizer data and the index. In a real-world deployment, nearly every HTTP server uses gzip compression which takes the wasm module size to 79MB, not great but it is acceptable IMO. One great solution to this is to use a quantized model, a
gte-smallquantized model is only 34MB. Unfortunately,wonnxdoesn’t supportint8model inference, partially due to the Matmul shader implementation usingmatCxR<T>matrix type which only supportsf32andf16floats. - Talking about this project to one friend, he suggested to reimplement
docVecas a browser extension! This would semantic search possible on ALL your web pages not only the one served! No idea how to build a browser extension but this could be fun. Thinking about it right now, I think that the tricky part will be to build the index on the fly. This is a time-consuming task: you need to parse the webpage, figure out the text, split it, and embed it efficiently (batching, probably a quantized model to reduce inference time) before ever thinking about query search. But, I mean… it is doable 😄 !